Unsupervised Image Retrieval using Convolutional Auto-encoder


Link to my Github repo containing the code
- Image Retrieval
- Loading Data
- Creating Convolutional Autoencoder
- Training the model
- Saving the model
- Visualizing the output of the auto encoder
- Clustering and optimizing for K
- Training Kmeans with 6 clusters
- Predictions
Loading Data
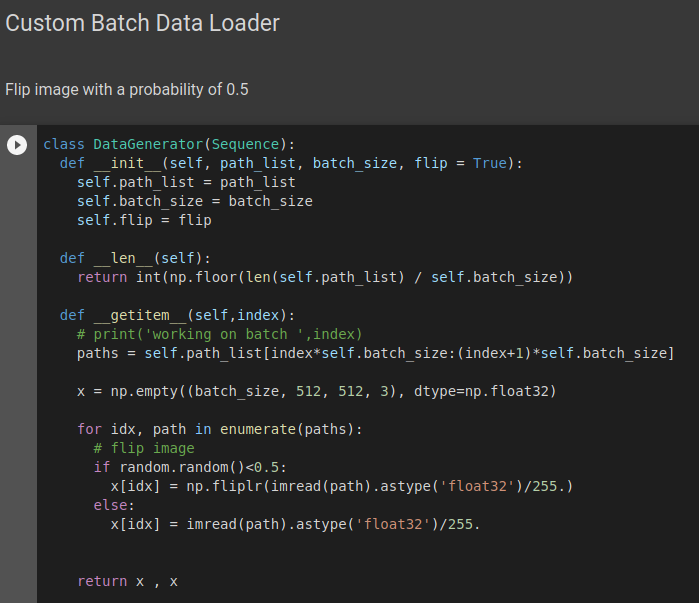
Lets create a custom data loader. This class is a type Keras.utils.sequence. it takes in a list of paths of dataset and batch size. outputs the numpy array with images batched and flipped with a random probability of 0.5. This type of data augmentation helps with training.
Creating Convolutional Autoencoder
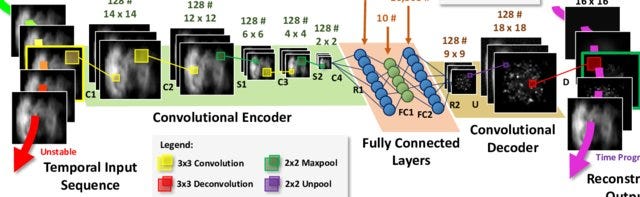
We start with a encoder block which takes the input images and convolve them into images with smaller size. Then use a densely connected neural net with 512 nodes. The output at this point represents the original image in an 512 Dim latent space. Now we build the decoder which takes this 512 dim vector and tries to rebuild the original image. This can be done by up sampling or Conv2D transpose.
Training the model
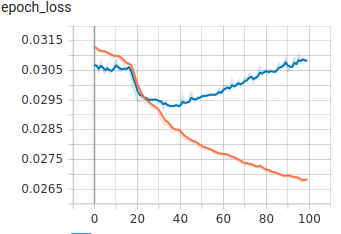
Now we have the data loader and the model we will see how training works.In the following graph the orange line is training loss and the blue line is the validation loss. As we train the training loss keeps decreasing, while the validation loss follows the training loss for a while but then goes back up. The lowest point in the validation loss is the maximum compressibility we can achieve with this architecture.
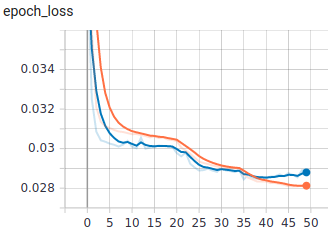
The following is the training for 50 epoch with data augmentation.
Saving the model
model.save(‘Conv_AE.h5’) save the model to the current working directory.
Visualising the output of the auto encoder
We can visualize the final output of the decoder.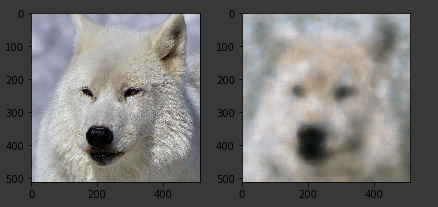
Clustering and optimizing for K
In cluster analysis , the elbow method is a heuristic used in determining the number of clusters in a data set. The method consists of plotting the explained variation as a function of the number of clusters, and picking the elbow of the curve as the number of clusters to use. The same method can be used to choose the number of parameters in other data-driven models, such as the number of principal components to describe a data set. -Wikipedia
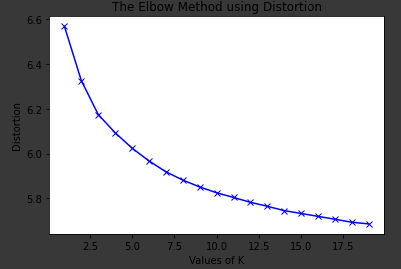
Predictions
With k as 6 we train a K-Means model to cluster the images. We take the query image and pass through the encoder. The output of 512 Dim vector is then passed through the Kmeans model and the number of the cluster this belongs to is predicted. Then we can query the similarity of this image to all the images in the cluster it belongs to.
Improvements
We can use the pretrained models like Efficientnet models as feature extractor and some supervised labeling can help in building a Triplet loss model.
Improvements
A good resource for supervised structure
https://neptune.ai/blog/content-based-image-retrieval-with-siamese-networks